
Breaking Silos - How Cloud Computing Enables Seamless Collaboration in Research
Exploring how cloud infrastructure breaks down geographic and institutional barriers, empowering researchers from different locations to work together more efficiently.

The potential of cloud computing encourages us to push the boundaries of collaboration and research, in this article I’ll take a look at some of the history of cloud computing, a few real world examples of how cloud computing has impacted projects and what we can do to help researchers and scientists in their desire for faster, more effective sharing and dissemination of data.
Cloud computing history
Today we'll examine how cloud computing enables seamless collaboration and research. But to do so, I want to take you back to the beginning—the beginning of computing, especially cloud computing—and examine how that laid the groundwork for what we consider distributed and seamless collaboration in computing today.
In the 1960s, the concept of 'utility computing' emerged. This was a visionary idea proposed by computer scientist J.C.R. Licklider, who envisioned a global computer network that would function like a utility, allowing users to access data and programs anywhere in the world. This concept, remarkably similar to the modern cloud computing model, laid the foundation for today's cloud computing.
One of the critical developments around this time was ARPANET, which appeared in 1969, the precursor to the Internet. Further on, in the 1970s and 80s, advancements in virtualization, operating systems, storage, and networking occurred. This allowed the World Wide Web, as we know it today, to be launched in 1991, connecting over a million machines to the Internet.
Over the next few years, quite a lot happened regarding computing speed, how people interacted with computers, and the number of people who had computers. That led to the dawn of modern cloud computing. The late 1990s and the early 2000s saw the emergence and the start of cloud services as we know them today. Salesforce, actually, in 1999, pioneered the concept of delivering enterprise applications via a website, marking the arrival of software as a service; they were the first people out there.
In 2000, Amazon Web Services was conceived, providing the ability to launch some storage and computational tasks. In 2006, Amazon introduced S3, SQS and EC2, the first commercial cloud service, as we know it today, allowing companies and individuals to rent computers to run their applications. Now, it wasn't to say that you couldn't do stuff like this before, but most of it was FTP-based or renting physical machines somewhere else, and EC2 really became the forefront of modern cloud computing.

Following that, 2007 to 2015 saw rapid growth and diversification in cloud adoption and, you know, the entry of more tech players. Google introduced the Google App Engine, offering free plans and low-cost computing services, which, you know, again, drove many people to use cloud computing. 2010, Microsoft entered the cloud market with Azure, supporting web and mobile app development. In 2011, IBM launched its intelligent cloud services. During this time, cloud computing began revolutionizing business operations, offering benefits such as reduced capital cost, improved efficiency, and more manageable IT management.
From 2016 onwards, cloud computing has become the mainstay of most businesses' operations. Yeah, various companies still have on-prem deployments or things that go in more generic data centres, but these days, most companies either leverage cloud services or leverage SaaS services that sit inside of cloud services. There are, though, these days, hybrid and multi-cloud environments that have become more common. Edge computing has emerged as an extension of cloud services where we get the computer as close to the user as humanly possible while still retaining the flexibility of cloud computing. We look at AI and machine learning, which have been integrated into cloud platforms, and they have to be because the sheer scale of the compute that is required to do the processing necessitates a large number of clusters, a large number of servers sat in large clusters inside of a data centre.
COVID-19 and the pandemic accelerated cloud adoption across these industries because no one was in an office anymore or in a data centre to maintain the servers, and so that really sped things up.
Today, cloud computing underpins most technological disruptions and has repeatedly proven its resilience, scalability, and flexibility. While it may experience occasional downtime, it remains a reliable and integral part of the services you interact with daily. According to Gartner, public cloud spending is expected to exceed 45% of all enterprise IT spending by 2026, up from less than 17% in 2021, a testament to its practical benefits and reliability.
As we look to the future, cloud computing continues to evolve, with emerging trends such as serverless computing, edge computing, and quantum computing on the horizon. The cloud's transformative power in enabling digital transformation across industries is set to grow even further, shaping the future of technology and business operations. This evolution inspires optimism and excitement for the future of technology.
Use cases over the years
I want to explore some real-life use cases where we've broken barriers with cloud computing and how it has advanced research. I first want to explore my experience after I started at NASA while working with a large genomics company.
This company had a lot of data, but it was all very much like on either researchers' laptops or shared drives that sat on generic infrastructure under people's desks. The problem with that is that users who want access to that data cannot see it, and when they get access to that data, they work in very siloed environments. They're not collaborating with other people. They're only interacting with other people once they get to a point where they want to be able to share their research so that other people can see it. That creates several problems when driving innovation and the research that underpins it.
So we came up with a plan where we were going to move these terabytes, maybe even petabytes of PDF documentation and Excel spreadsheets and reports, everything, up into AWS. We ordered a Snowball, one of those drives that you can get sent to your business, which you can then use to upload data more seamlessly, load it with data and then send it back to AWS to get it into S3. You have to bear in mind that this was about 10 years ago, and a lot has changed since then, but we got all this data into S3 and then looked at the tooling.
We want to make it all searchable. So, the first thing we had to do was index all of the PDF documentation, including everything that wasn't particularly indexable back then. Standards have changed quite a bit. Getting data out of PDFs in a structured format that would allow for a cohesive search was complex, so we built some tooling around the data extraction and got the research data in there. Then, we had to create user interfaces for the search.
We then had to build tooling to allow researchers to access that data and really start sharing it with each other. Now, it was in the cloud, and anyone in the business could access it.
Of course, that had a knock-on impact because we had to implement role-based security tied into their enterprise authentication mechanism. Cognito didn't exist then, so we had to roll our own. That took weeks. However, it allowed seamless access to all this data that the business otherwise had hidden on servers that were completely inaccessible to people. And it revolutionized how the company did its research going forward.

Next, I'd like to jump forward to almost the present day. For the last four years at NASA, I worked on an open-source tool called Pixelize.
Now, most people don’t know anything about X-ray spectroscopy. I don't know anything about X-ray spectroscopy, but we did write tooling that allowed a very distributed team access to not quite real-time data, but not far off it, as fresh as we could make it from NASA’s latest Mars Rover. They were distributed from various parts of Australia, North America, and Europe, literally spanning the globe.
We would get data coming down from the Mars rover, from the PIXL instrument on Mars 2020, NASA Perseverance, and we would stick that data through many different pipelines based mainly on Lambda functions at the time. So, we would process that data and then turn it into a different data structure that suited our application, which we built from the ground up, with a huge amount of input from our end users, the researchers. This allowed the researchers to access this data and make real-time decisions that would have taken 48 hours by the time you get the data, process it, and then analyze it with colleagues. We'd really turned it into something that allowed users to get that data within about 10 minutes of landing and run some extra processing over the top, which we'd optimized again multiple days down to a few minutes by implementing a bunch of parallel computing techniques.
That would allow people to share data in a Google Docs style but for research, which we'll touch upon later. They could really share that data, discuss it with other people, and then make a go-no-go decision on whether they would do more research in that spot or continue. This explores how cloud infrastructure breaks down geographic and institutional barriers, allowing researchers from different locations to work together more efficiently. It was unique and got a lot of attention internally at NASA.
Distributed computing
A lot is being said about the return to the office and people working collaboratively now; Amazon is a case in point. I want to look at distributed computing; when I say distributed computing, I don't mean large Spark clusters. That's one aspect of distributing compute, being able to scale up and push the boundaries of the amount of compute you're using because you're leveraging the cloud.
The other aspect of distributed computing is that people are often distributed globally, especially in research. Collaborations between different universities are part of research; they allow people to distribute the cost and the time taken to do the tasks by leveraging different departments at different universities or different researchers at different universities, and these researchers can literally be in Europe and North America and Australasia and so on and so on because that also gives groups access to a range of different research funds and grant angles, which is a collaboration in itself!
This means that you do have to do distributed computing and develop novel ways for people to share their research and insight. One of the things that we make a lot of use of these days is cloud-based communications. Slack, Teams, and even Google Hangouts, if you have to. They all provide a service allowing distributed communication and access to files, people, and whiteboards. You name it, and you can do it. And so that has really been something that has been driven, especially post-COVID, in how people interact with other people online and the features and the functionality that the available software, often for free, now brings.
From a research perspective, the other aspect of distributed computing is collaborating on the data and research output. Collaborative document editing is one of the big things that have come along in the past decade. If you think of Google Docs, Google Sheets, or Office 365, and there are also open-source versions of this stuff that you can host on your own hardware, it really is mainstream these days and not just the purview of the big tech corps. In day-to-day life, people make a lot of use of these and may not even notice it. You may use Word on your laptop but be operating on a document that's sat inside of SharePoint, which someone else also opens and edits in real-time, so you can work on collaborative documentation, perhaps without even realizing it. This is, in essence, what I mean by distributed computing, allowing researchers to access data in a way that facilitates other people's insight, impacting the stuff they do daily.
How you do that often requires novel methods and different ways people think about how they will share that data and how they will interact with it. It's not to say that you can't do it; it's to say that you need to have the opportunity to think about that stuff and be able to build out software that's targeted specifically for that, to allow for people to really understand the power of distributed computing, and take them away from what they do currently on a day-to-day basis, and really propel them into a different way of going about their research, and their learning, and their understanding.
Tailored Interfaces
This brings me to the crux of this topic, tailored interfaces. Most of what we do today is web-based regarding cloud computing and how we interact with systems. Behind the scenes, there might be a lot of processing going on, but often, the triggers and the stuff that actually gets it going is a web interface. It's a human clicking a button. It's a human writing a query. It's a human doing something. And so, researchers have had a period where they've often done the same thing day in, day out. And invariably, if you're a researcher with some technical background, you will probably use Jupyter Notebooks. You may use them locally. You may use them in Databricks or Azure Lakehouse, there are many different ways of interacting with notebooks. But quite often, that is the limit of the interaction with the data that you have because there's no interface to allow you to really deal with that data in any other way.
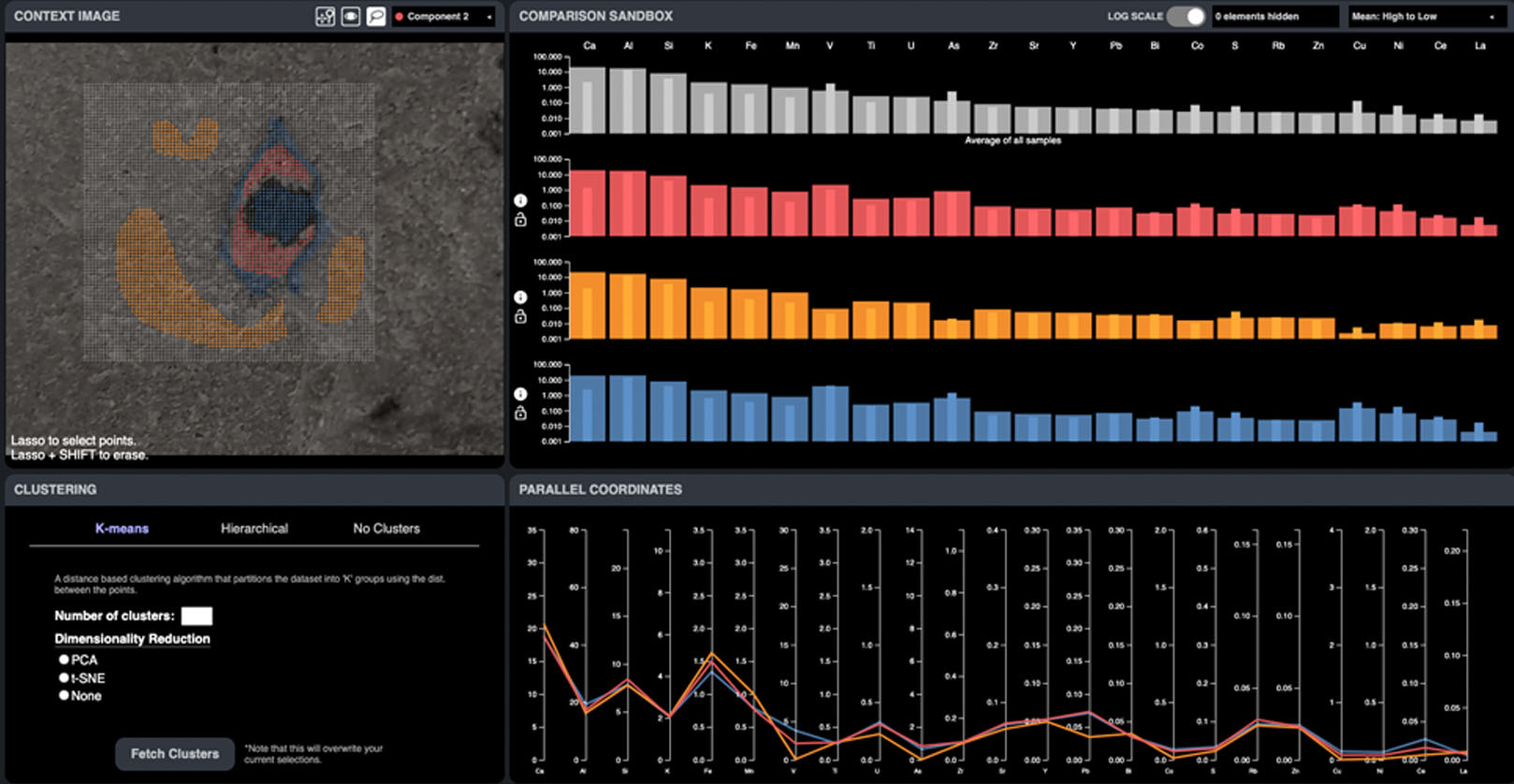
If I go back to the Pixlise project that I mentioned earlier, often the researchers would do some processing inside of a Jupyter Notebook, output that information to a CSV file, load it up inside of Excel, do some more processing, create some graphs, and then share that research. That is how they would do their research and collaboration by sharing Excel notebooks by email. One of the things we came across during the project was how we can generate or create user interfaces that push the boundaries of how researchers interact with their data. How can we create interfaces that allow researchers to access the data points they need without having to write a bunch of custom queries, write a whole export chain to Excel and then do some more processing? This is key because researchers, being researchers, have yet to really think about the ways that they could interact with the data other than inside of a notebook or inside of an Excel spreadsheet.
Part of our job as cloud evangilists is to open the eyes of researchers, allow them to see the possibilities out there, and ask what they think is an unachievable goal because that pushes the boundaries of distributed computing. It's what really pushes the limits of how we interact with the data stored inside the cloud and how we really unleash the power and capabilities out there. If everybody continues to interact with data similarly, they open up a notebook, even in the cloud, write some queries and then output a chart at the end; that's not innovation. That's just continuing the same process and pattern that people have done locally but in a remote cloud environment.
And in some cases, especially for smaller projects or more bespoke things, that's a good way of doing it. I'm not talking ill of the notebook environment, but if there's the budget and the scale and the requirement for research to be ongoing for a period of time, talk to those researchers and really understand how they want to interact with their data, what's important to them, and what interfaces they could possibly leverage that allow them to both reduce the complexity of what they're doing but also speed up their access to that data because, at the end of the day, writing queries is often a slow process as you work out what part of the query works and then roll it up and then combine it with another piece of query writing. And so allowing people to think big and think of the possibilities is super essential to allow us to break these silos and enable collaboration in research.
Conclusion
I want to wrap this up by going through the different phases of how researchers could interact with their data. We've looked at the history of cloud computing. We've looked at some real-life examples of getting data out of local systems and into the cloud, which really fosters collaboration. And that's step one of this challenge, data gets into the cloud so that it can be shared easily.
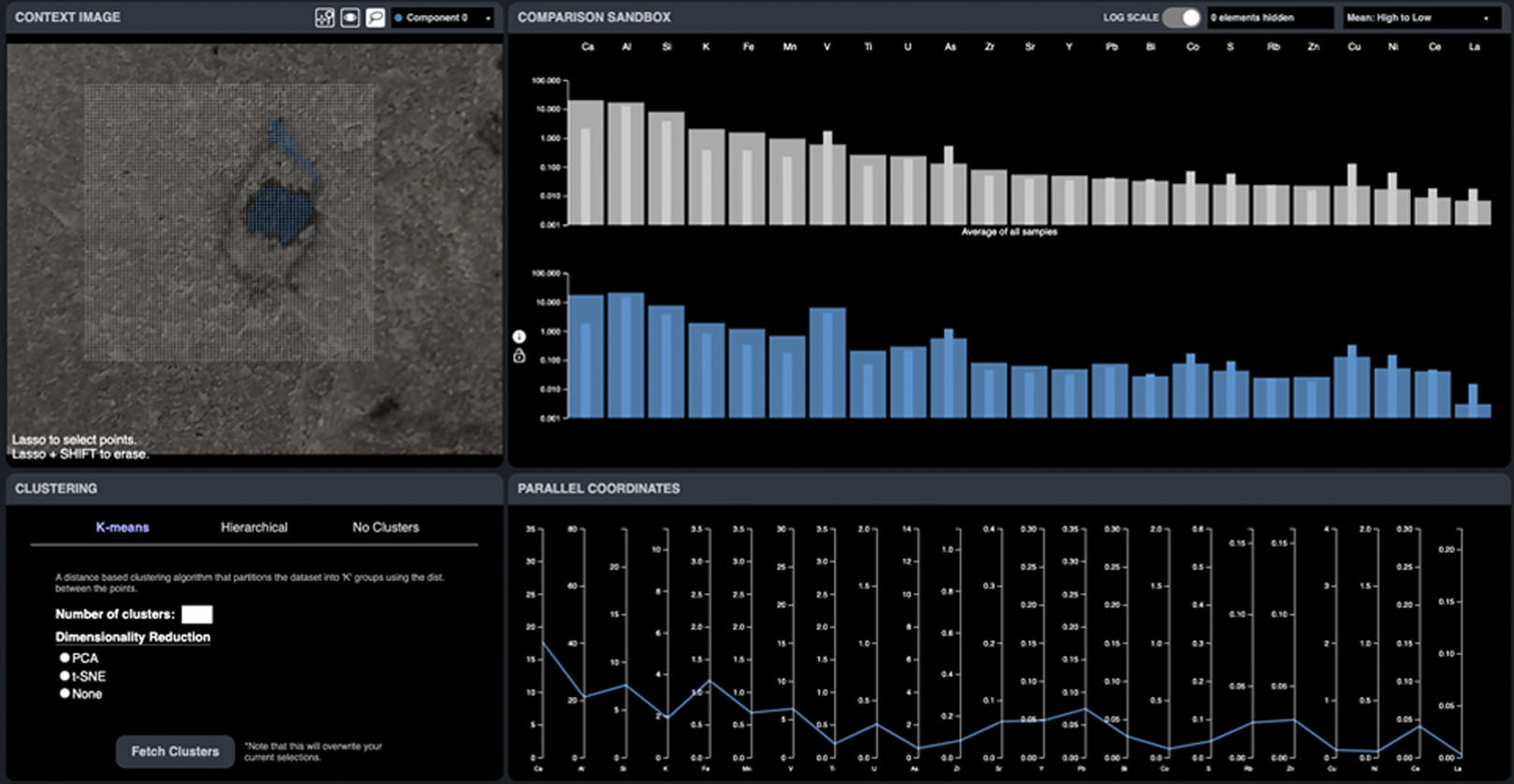
If step two of that challenge allows people access via notebooks, that is fine. However, consider for a period of time if there is a better way for people to interact with that data and collaborate in real-time on that data. And if the tooling doesn't exist, sit down with researchers and really dig into what's important, what drives them, and how you can make their lives easier. Because we can break those silos.
We can really drive innovation and collaboration in the research environment. But, the researchers need to be able to drive that way of operating. And they must be stakeholders in the process.
If you would like to find out more we also have a case study over on our website.